TLDR: Embedding models open up a world of possibilities for self-hosted recommendation systems without the need for a large user base.
A gift that came with Large Language Models (LLMs) is embedding models. Imagine a black box that takes text as input and converts it into a numeric representation, where similar things have similar numbers.
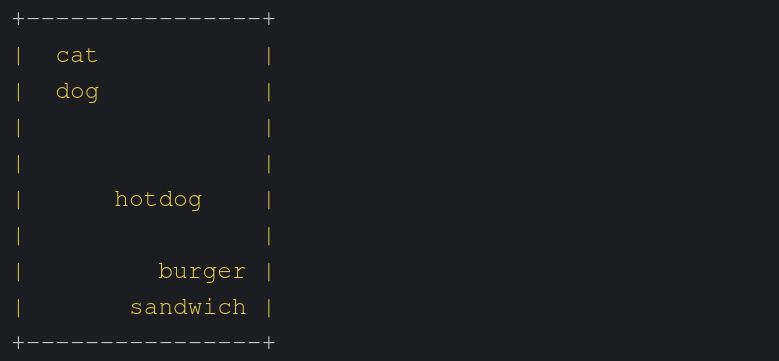
For example, in two dimensions, we could pass the following words to an embedding model: sandwich, burger, cat, dog, hotdog. And we could get the following embedding representation:
+----------------+
| cat |
| dog |
| |
| |
| hotdog |
| |
| burger |
| sandwich |
+----------------+
Where we see food items clustered together and animals clustered together, with hotdogs being classified as a food item but closer to “dog”. And this gets even cooler when we have more dimensions, where the model can start capturing more complex relationships. Or when we have an embedding model that takes images as input.
You probably can already imagine some applications for embedding models. The most popular ones are:
- Image search engines, where you can search for images similar to a given one or with text.
- Translation services, where you can translate a word to another language by looking for the closest word in the embedding space. And yes, as you might have guessed, embedding models can support multiple languages.
- Inexact search engines, where you can search for text or concepts without the need for an exact match in the words used.
But the most exciting one for selfhosters is recommendation systems. Usually, these are hard to self-host because they require a large user base to work well (e.g., YouTube). Because they use collaborative filtering, where they recommend things to you based on what other users with similar tastes liked, which is not the case when self-hosting.
Thanks to embedding models, we can now build recommendation systems based only on the embeddings. As an example project, I built a recommendation system for RSS feed articles. I always struggled with keeping up with all the feeds and not because I found most articles interesting. So I built a system that would recommend me articles based on the ones I usually read (and some random ones for serendipity).
The system works just by computing the embeddings of the article titles and descriptions, clustering them, and then filtering all RSS feeds for articles that are close to the cluster of the articles I usually read. You can find the code for this project at m0wer/rssfilter.
Same way embedding models can be used to recommend articles, they can be used to recommend products, movies, music, or anything that can be represented as text or images.
And this opens up a world of possibilities for self-hosted recommendation systems that were not feasible before.